The CSV disassembler is a system artifact in Link 3.0. Its purpose is to convert CSV files to XML for further processing. Be advised that it only handles delimited files, not positional ones.
The CSV disassembler uses an ordinary XML schema (XSD) for determining the XML structure it needs to convert the CSV to. Additionally it has a number of configuration options, some mandatory, some not, which tells it how to parse the CSV file. Keep in mind that the disassembler needs to be configured explicitly for each CSV format, so CSV files can only be processed via channels that allow for the setup of an InitConfiguration (e.g. incoming transport location).
Configuration
The CSV disassembler configuration looks like this:
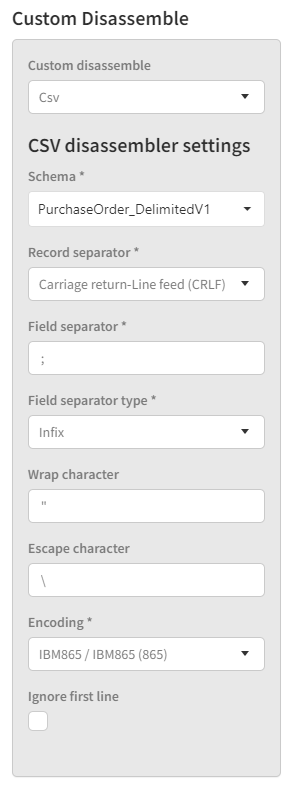
Schema
This is the XML schema (XSD) the disassembler will use to determine the structure of the XML file the CSV should be disassembled into. The schema needs to be deployed to Link as an XML artifact. More about the schema later.
Record separator
This indicates the separator used to delimit records from one another in the CSV file. Current options are Carriage Return (CR), Line Feed (LF) and Carriage Return-Line Feed (CRLF). If necessary, this can easily be expanded in the future.
Field separator
This indicates the separator used to delimit fields from one another within a record. This is a single character value.
Field separator type
This indicates how the field separator is used. There are currently two option, Infix (one separator between each field) and Postfix (one separator after each field).
Wrap character
Some CSV formats use a wrap character around some or all field values. If so, the wrap character used should be indicated here, so the values can be “unwrapped” in the resulting XML.
Escape character
Some CSV formats use an escape character, primarily so fields can contain the field delimiter character if necessary.
Encoding
This indicates which encoding the CSV file should be interpreted as. Since CSV files do not have any standardized way of exposing their encoding, it is necessary to know the encoding beforehand, in order to interpret the file correctly.
Ignore first line
This checkbox simply tells the parser to skip the first line of the file. It is not uncommon for the first line in a CSV file to contain the “column names” used by the records below, but those names are rarely interesting in an integration scenario. Rather than making a header record for them in the XML format which will never be used for anything, you can choose to simply skip the first line in the parsing.
Schemas
The Link3 CSV disassembler (and assembler) uses normal XML schemas (XSDs) to determine how to convert the CSV file to XML.
Here is a simple example to demonstrate.
CSV file
20230120005;1;160;65,56;20230120120000;01234;275811025
276051;20230119120000;28590;42;420
276070;20230119120000;28590;42;420
276067;20230119120000;28590;42;420
276049;20230119120000;27621;20;427,82
276179;20230119120000;27621;14;291,4
This CSV has a header record and a number of line records.
Xml schema
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1" targetNamespace="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="ReceiveAdvice">
<xs:complexType>
<xs:sequence>
<xs:element name="Header">
<xs:complexType>
<xs:sequence>
<xs:element name="TruckLoadID" type="xs:string" />
<xs:element name="TotalPallet" type="xs:string" />
<xs:element name="TotalBoxes" type="xs:string" />
<xs:element name="TotalKg" type="xs:string" />
<xs:element name="FileCreateDate" type="xs:string" />
<xs:element name="CustomerNo" type="xs:string" />
<xs:element name="IdentNo" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="Lines">
<xs:complexType>
<xs:sequence>
<xs:element maxOccurs="unbounded" name="Line">
<xs:complexType>
<xs:sequence>
<xs:element name="PalletNo" type="xs:string" />
<xs:element name="ButcherDate" type="xs:string" />
<xs:element name="ArticleNo" type="xs:string" />
<xs:element name="BoxCount" type="xs:string" />
<xs:element name="NetWeight" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
As you can see, the schema is pretty simple. It just defines the record types and their relationship to each other in the structure. It also wraps the line records in a structure node. This is not technically necessary, but many people prefer it that way.
Disassembled file
When the above example file is disassembled using the above schema, this is the result:
<?xml version="1.0" encoding="utf-8"?>
<ReceiveAdvice xmlns="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1">
<Header xmlns="">
<TruckLoadID>20230120005</TruckLoadID>
<TotalPallet>1</TotalPallet>
<TotalBoxes>160</TotalBoxes>
<TotalKg>65,56</TotalKg>
<FileCreateDate>20230120120000</FileCreateDate>
<CustomerNo>01234</CustomerNo>
<IdentNo>275811025</IdentNo>
</Header>
<Lines xmlns="">
<Line>
<PalletNo>276051</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276070</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276067</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276049</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>27621</ArticleNo>
<BoxCount>20</BoxCount>
<NetWeight>427,82</NetWeight>
</Line>
<Line>
<PalletNo>276179</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>27621</ArticleNo>
<BoxCount>14</BoxCount>
<NetWeight>291,4</NetWeight>
</Line>
</Lines>
</ReceiveAdvice>
Schema rules
There are a few things to note about how the disassembler interprets the XSD and how this affects its behavior.
minOccurs attribute
If a field in the schema is set to have minOccurs=0, the field is considered optional by the disassembler. As such, if the equivalent field in the CSV is empty, the disassembler will not generate the field in the XML. Please note that 0 is the only value of minOccurs that the disassembler looks at. Any field that has another value in minOccurs, or that does not have a minOccurs attribute at all is simply considered mandatory, and will always be generated, even if it is empty. From a schema standpoint, this is equivalent to a field having minOccurs=1 and maxOccurs=1, either explicitly or implicitly. To be clear, if a field in the schema has minOccurs=3, the disassembler treats it as if it was minOccurs=1.
Also note that minOccurs is only taken into consideration for fields, not records. The disassembler treats all records as having implicitly minOccurs=0. As such, any minOccurs attribute on a record in the schema will be ignored by the disassembler.
maxOccurs attribute
The maxOccurs attribute is only used for records. As with minOccurs, only a single value is taken into account, namely maxOccurs=unbounded. This is considered an indication that the record is repeating, and any other value (or lack thereof) is considered equivalent to maxOccurs=1.
default attribute
The default attribute can be used on fields in the schema to indicate a default value which will be used by the disassembler if the equivalent field in the CSV is empty.
Record matching
It is important to note how the disassembler determines the type of record a given line in the CSV has.
The disassembler basically moves sequentially through the record types defined in the schema, and compares the number of fields in the record to the number of fields in the current line of the CSV. If it is a match, it generates that record in the XML output and moves on to the next record definition and the next line in the CSV. If it is not a match, it moves on to the next record definition and tries to match that.
The exception to that rule is if the record is defined as repeating (maxOccurs=unbounded), in which case it keeps trying to match the next lines in the CSV against the same record type until the match fails, then it moves on to the next record definition.
What this means from a practical standpoint is that any record definition immediately following a repeating record must have a different number of fields than the repeating record, otherwise the disassembler will not be able to tell that it is not the same record type as the one it is already trying to match.