The CSV assembler is a system artifact in Link 3.0. Its purpose is to convert XML documents to CSV files prior to sending them to a recipient. Be advised that it only handles delimited files, not positional ones.
The CSV assembler uses an ordinary XML schema (XSD) for determining how to convert the XML document to CSV. Additionally it has a number of configuration options, some mandatory, some not, which tells it how to generate the CSV file. The assembler is an itinerary step and needs to be configured explicitly for each format. As such, the most common scenario will be to configure it on the outgoing document configuration, by adding the CSV itinerary step to the itinerary and configuring it there. Should you have a scenario where the same format is going to different recipients, but the recipients need the files in different encodings, you can check the box “Configure on distribution” in the itinerary step configuration on the document configuration itinerary, and then configure the step on the distributions instead. That way, each recipient can get the same format with their preferred encoding (or separators for that matter).
Configuration
The CSV assembler configuration looks like this:
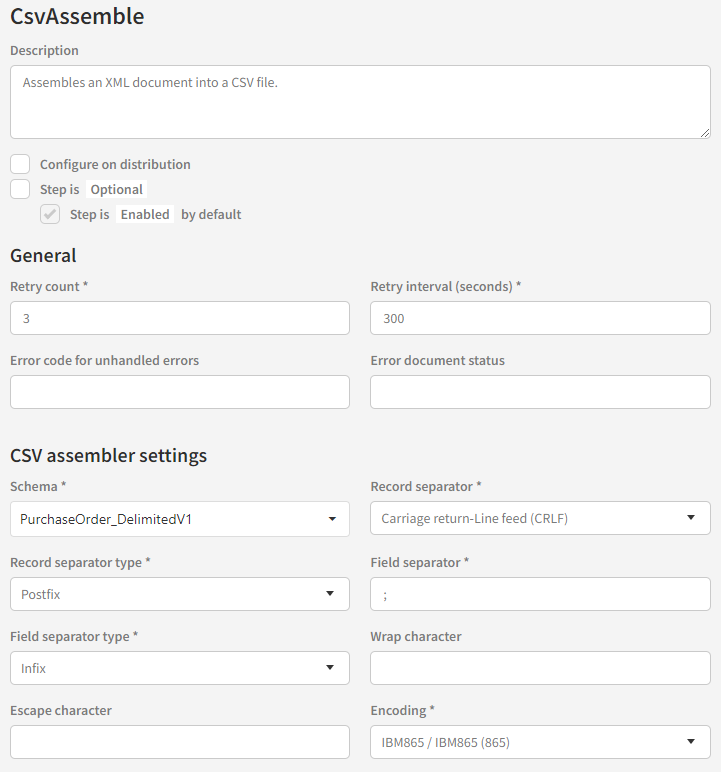
Only the fields in the “CSV assembler settings” section are specific to the assembler.
Schema
This is the XML schema (XSD) the assembler will use to determine how to convert the XML document to CSV. The schema needs to be deployed to Link as an XML artifact. More about the schema later.
Record separator
This indicates the separator used to delimit records from one another in the CSV file. Current options are Carriage Return (CR), Line Feed (LF) and Carriage Return-Line Feed (CRLF). If necessary, this can easily be expanded in the future.
Record separator type
This indicates how the record separator is used. There are currently two options: Infix (one separator between each record) and Postfix (one separator after each record). Basically it indicates whether the resulting CSV file should have an empty line at the end or not.
Field separator
This indicates the separator used to delimit fields from one another within a record. This is a single character value.
Field separator type
This indicates how the field separator is used. There are currently two options: Infix (one separator between each field) and Postfix (one separator after each field).
Wrap character (optional)
If a wrap character is defined in the configuration, all fields defined in the XML schema as having the type xs:string will have their values wrapped in this character in the CSV.
Escape character (optional)
Some CSV formats use an escape character, primarily so fields can contain the field delimiter character if necessary. It also allows wrapped fields to contain the wrap character. Keep in mind that if one or more of the fields in the XML do contain any of these characters and no escape character is defined in the configuration, the resulting CSV file will not be valid.
Encoding
This indicates which encoding the resulting CSV file should be encoded with.
Schemas
The Link3 CSV assembler uses normal XML schemas (XSDs) to determine how to convert the XML file to CSV.
Here is a simple example to demonstrate.
Xml document
<?xml version="1.0" encoding="utf-8"?>
<ReceiveAdvice xmlns="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1">
<Header xmlns="">
<TruckLoadID>20230120005</TruckLoadID>
<TotalPallet>1</TotalPallet>
<TotalBoxes>160</TotalBoxes>
<TotalKg>65,56</TotalKg>
<FileCreateDate>20230120120000</FileCreateDate>
<CustomerNo>01234</CustomerNo>
<IdentNo>275811025</IdentNo>
</Header>
<Lines xmlns="">
<Line>
<PalletNo>276051</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276070</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276067</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>28590</ArticleNo>
<BoxCount>42</BoxCount>
<NetWeight>420</NetWeight>
</Line>
<Line>
<PalletNo>276049</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>27621</ArticleNo>
<BoxCount>20</BoxCount>
<NetWeight>427,82</NetWeight>
</Line>
<Line>
<PalletNo>276179</PalletNo>
<ButcherDate>20230119120000</ButcherDate>
<ArticleNo>27621</ArticleNo>
<BoxCount>14</BoxCount>
<NetWeight>291,4</NetWeight>
</Line>
</Lines>
</ReceiveAdvice>
Xml schema
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1" targetNamespace="http://Customer.ReceiveAdvice.Schemas.ReceiveAdvice_DelimitedV1" xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="ReceiveAdvice">
<xs:complexType>
<xs:sequence>
<xs:element name="Header">
<xs:complexType>
<xs:sequence>
<xs:element name="TruckLoadID" type="xs:string" />
<xs:element name="TotalPallet" type="xs:string" />
<xs:element name="TotalBoxes" type="xs:string" />
<xs:element name="TotalKg" type="xs:string" />
<xs:element name="FileCreateDate" type="xs:string" />
<xs:element name="CustomerNo" type="xs:string" />
<xs:element name="IdentNo" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="Lines">
<xs:complexType>
<xs:sequence>
<xs:element maxOccurs="unbounded" name="Line">
<xs:complexType>
<xs:sequence>
<xs:element name="PalletNo" type="xs:string" />
<xs:element name="ButcherDate" type="xs:string" />
<xs:element name="ArticleNo" type="xs:string" />
<xs:element name="BoxCount" type="xs:string" />
<xs:element name="NetWeight" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
As you can see, the schema is pretty simple. It just defines the record types and their relationship to each other in the structure.
Assembled CSV file
20230120005;1;160;65,56;20230120120000;01234;275811025
276051;20230119120000;28590;42;420
276070;20230119120000;28590;42;420
276067;20230119120000;28590;42;420
276049;20230119120000;27621;20;427,82
276179;20230119120000;27621;14;291,4
Schema rules
There are a few things to note about how the assembler interprets the XSD and how this affects its behavior.
minOccurs attribute
The assembler does not use the minOccurs attribute for anything. However, as the XSD can also be used to validate the XML document itself, it can be useful or even necessary to mark certain records or fields as optional by setting minOccurs=0.
As far as the assembler is concerned, it simply generates the records that are present in the XML document, while ignoring those that are not. Keep in mind that for a given record type the assembler generates all fields defined by the schema for that record type, regardless of whether or not all of the fields are present in the XML record.
maxOccurs attribute
The maxOccurs attribute is not used by the assembler at all.
default attribute
The default attribute can be used on fields in the schema to indicate a default value which will be used by the assembler if the equivalent field in the XML is not present. Keep in mind that if the field is present in the XML, the disassembler will use the value of the XML field, even if it is empty. The assumption is that if a field is present but empty, this is done intentionally. The default value is only used if the field is not present at all.