Duplicate Check
Sometimes you might want to check whether an incoming document already exists in your Link solution to avoid duplicates. This is done using duplicate check, which is an advanced feature available on distributions. There are several different types of duplicate checks. These will all be described in detail on this page. Depending on your permissions, some types may not be available.
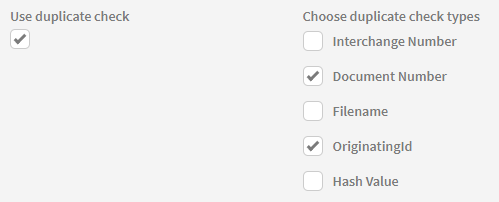
To enable duplicate check, tick the checkbox 'Use duplicate check', which will allow you to select the duplicate check types you want to use to. You can select multiple duplicate check types at once.
Interchange Number Check
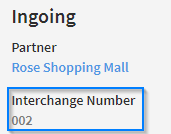
Checking this option will determine whether a document with the same Interchange Number already exists in the database. The Interchange Number is described in more detail on the 'Tracking Search Details' page. In short it is a number that is present in an Edifact document. In the example screenshot below, the interchange number is "002", which is taken from UNB segment of the incoming Edifact message.
Document Number Check
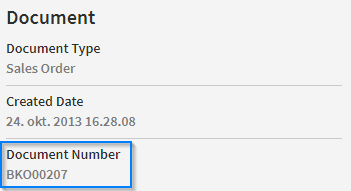
Checking this option will determine whether a document with the same Document Number already exists in the database. The Document Number can be found under the 'Document' section on the 'Tracking Details Page'. It can also be viewed on the 'Tracking Search Result' page in the first column. As mentioned on the 'Tracking Search Details' page, it is a unique number given to a document, which may vary between Document Types, e.g. a Buyer Order Number or an Invoice Number.
Filename Check
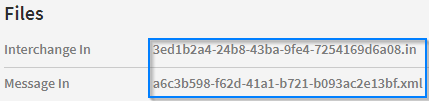
Checking this option will determine whether a document with the same filename already exists in the database. The filename of a document can be found on the 'Tracking Search Details' page under the 'Files' section.
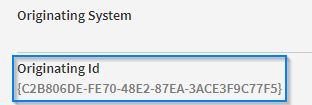
OriginatingId Check
Checking this option will determine whether a document with the same Originating Id already exists in the database. It refers to the id of the transmission from the originating system if such have been configured. You can find it under the 'Document' section on the 'Tracking Details Page'.
Hash Value Check
Hash value check uses the hash value of the first 30.000 bytes of a file when checking for doublets. Be aware that the doublet check is first done on the Message in the file. This means that newlines, tabs and other non-visible characters could have been removed before the doublet check.
For how long back in time does the duplicate check work and under which circumstances?
Here are some statements that can help with your understanding of the duplicate check functionality:
-
Duplicate check values are stored in relation to the distribution where you setup duplicate checks. This also means that if you delete the distribution and create it again, the documents that were processed by the first distribution will not be checked against the documents that were processed by the second distribution.
-
If you Edit a distribution and disable a duplicate check type in a period of time and then enable it again. The documents that are processed in that period of time will NOT be subject to duplicate check for the duplicate check type you disabled.
-
If you Edit a distribution and change something that is not related to the duplicate check functionality like the "Format/Variant/Version" on either the "From Format" or "To Format". This will not affect the duplicate check functionality.
-
When a document has been deleted by the Maintenance job, that documents duplicate check values are deleted with it. This means that an identical document will not be seen as a duplicate. Note: There is a "hidden" feature where its possible to delete duplicate check values earlier (not later, unfortunately) than when the document is deleted (the hidden configuration key description is "Days to keep duplicate check records"). It could make sense to delete documents but keep duplicate check values but this will require a feature request.
Content on this page: